
log.Sehee
[데이터 취업 스쿨 스터디 노트] EDA 학습과제 1 / 스타벅스 이디야 매장 데이터 분석 본문
EDA 학습과제 1 : 이디야 매장의 위치는 스타벅스 매장의 위치와 관련이 있는가?
1. 스타벅스 매장정보 정리
from selenium import webdriver
from selenium.webdriver.common.by import By
url = 'https://www.starbucks.co.kr/store/store_map.do?disp=locale'
driver = webdriver.Chrome()
driver.get(url)
서울 지역 선택
# 서울 지역 선택
seoul_select = driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')
seoul_select.click()
전체 구 선택
# 전체 구 선택
all_select = driver.find_element(By.CSS_SELECTOR, '#mCSB_2_container > ul > li:nth-child(1) > a')
all_select.click()
필요한 정보 가져오기
# 필요한 정보 가져오기
store_list_raw = driver.find_element(By.CSS_SELECTOR, '#mCSB_3_container > ul')
store_list = store_list_raw.find_elements(By.TAG_NAME, 'li')
store_list[0].text.split('\n')
for문으로 오류 없는지 체크, 스크롤 시 내용 로딩으로 데이터를 가져올 수 없음
# 스크롤 시 내용 로딩으로 설계되어 데이터를 가져올 수 없음
for i in store_list[:5]:
print(i.text.split('\n'))
container div의 style: top 값으로 스크롤 조정이 됨을 확인, top 값 조정 테스트
# style 태그의 top값으로 스크롤 위치가 변경됨을 확인, top값 조정이 되는지 체크
height = -200
scroll = driver.find_element(By.CSS_SELECTOR, "#mCSB_3_container")
driver.execute_script(f"arguments[0].style.top = '{height}px';", scroll)
데이터 가져오기
# 빈 리스트에 데이터별로 저장
store_name = []
address = []
gu = []
height = 0
for store in store_list:
try:
# 스크롤 이동
driver.execute_script(f"arguments[0].style.top = '{height}px';", scroll)
# 데이터 저장
data = store.text.split('\n')
store_name.append(data[0])
address_info = data[1].split(' ')
address.append(' '.join(address_info[:-1]))
gu.append(address_info[1])
# 정보가 들어있는 li 태그의 height값 101
height -= 101
# 디버깅
except Exception as e:
print(store.text, '오류발생', e)
break
데이터 확인
# 데이터 확인
print(len(store_name), len(address), len(gu))
print(address[:3])
DataFrame으로 정리하기
# DataFrame으로 저장
import pandas as pd
data = {
'지점명': store_name,
'주소': address,
'구': gu
}
starbucks_df = pd.DataFrame(data)
starbucks_df.head()
스타벅스 웹페이지 닫기
# 스타벅스 매장찾기 페이지 종료
driver.quit()
2. 이디야 매장정보 정리
url = 'https://www.ediya.com/contents/find_store.html'
driver = webdriver.Chrome()
driver.get(url)
주소찾기 클릭
# 주소찾기 선택
find_address = driver.find_element(By.CSS_SELECTOR, '#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a')
find_address.click()
검색 테스트
# 검색 테스트
keyword = driver.find_element(By.CSS_SELECTOR, '#keyword')
keyword.clear()
keyword.send_keys('강남구')
search = driver.find_element(By.CSS_SELECTOR, '#keyword_div > form > button')
search.click()
필요한 정보 가져오기
# 필요한 정보 가져오기
store_list_raw = driver.find_element(By.CSS_SELECTOR, '#placesList')
store_list = store_list_raw.find_elements(By.TAG_NAME, 'li')
store_list[1].text.split('\n')[1].split(' (')
스타벅스 매장정보로 얻은 구 데이터 사용하여 이디야 매장정보 검색
# 스타벅스 매장정보로 얻은 구 데이터를 사용
gu_list = starbucks_df['구'].unique()
데이터 가져오기
import time
store_name = []
address = []
gu = []
# 구 입력하여 검색, 나온 정보를 리스트에 저장
for g in gu_list:
try:
keyword.clear()
keyword.send_keys(f'서울 {g}')
search.click()
time.sleep(1)
store_list = store_list_raw.find_elements(By.TAG_NAME, 'li')
for store in store_list:
store_info = store.text.split('\n')
store_name.append(store_info[0])
address_info = store_info[1].split(' (')[0]
address.append(address_info)
gu.append(address_info.split()[1])
except Exception as e:
print(g, '오류발생', e)
break
이 부분에서 검색 키워드를 '서울 강남구' 처럼 구 앞에 '서울'을 붙여야했는데
그냥 구 이름으로 검색하여 검색 결과가 너무 많다는 오류를 많이 보았다.
for문을 계속 돌려보다가, 검색창에 가서 직접 구 이름들을 검색해본 뒤 문제 파악, 키워드 앞에 '서울'을 붙여주었다.
데이터 확인
# 데이터 확인
print(len(store_name), len(address), len(gu))
print(store_name[:5])
DataFrame 정리
# DataFrame으로 저장
data = {
'지점명': store_name,
'주소': address,
'구': gu
}
ediya_df = pd.DataFrame(data)
ediya_df.head()
이디야 웹페이지 닫기
driver.quit()
3. 이디야 매장은 스타벅스 매장 근처에 있는가?
googlemaps를 사용하여 스타벅스 매장의 위도, 경도 정보 저장
# 위도, 경도 저장
import googlemaps
gmaps_key = 발급받은 API키
gmaps = googlemaps.Client(key=gmaps_key)
for i, row in starbucks_df.iterrows():
tmp = gmaps.geocode(row['주소'], language='ko')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
starbucks_df.loc[i, 'lat'] = lat
starbucks_df.loc[i, 'lng'] = lng
starbucks_df.head()
이디야 매장의 위도, 경도 정보 저장
for i, row in ediya_df.iterrows():
tmp = gmaps.geocode(row['주소'], language='ko')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
ediya_df.loc[i, 'lat'] = lat
ediya_df.loc[i, 'lng'] = lng
지도에 스타벅스 매장과 이디야 매장을 표시하여 육안으로 위치 연관성 확인해보기
import folium
m = folium.Map(location=[37.565, 126.988], zoom_start = 12.5)
for idx, row in starbucks_df.iterrows():
lat, lng = row['lat'], row['lng']
folium.CircleMarker(
location = [lat, lng],
radius = 3,
color = 'green',
weight = 1,
fill = True,
fill_color = 'darkgreen',
fill_opacity = 0.5
).add_to(m)
for idx, row in ediya_df.iterrows():
lat, lng = row['lat'], row['lng']
folium.CircleMarker(
location = [lat, lng],
radius = 3,
color = 'blue',
weight = 1,
fill = True,
fill_color = 'darkblue',
fill_opacity = 0.5
).add_to(m)
m
위 지도의 스타벅스와 이디야 매장의 분포로 보았을 때, 스타벅스 매장의 위치와 이디야 매장의 위치는 엇비슷해보인다.
하지만 카페 매장은 대부분 대로변에 존재하며, 상권에 몰려있을 가능성이 있어 육안으로 지역마다 분포를 확인하는 것에는 한계가 있다고 판단해 이디야 매장 근처 200m에 스타벅스 매장이 얼마나 존재하는지 정리하려 한다.
위도와 경도 정보로 매장 간 거리 계산하기
# 위도와 경도로 거리를 계산할 수 있다.
from geopy.distance import geodesic
data, t_f = [], []
for _, ediya in ediya_df.iterrows():
count = 0
for _, starbucks in starbucks_df.iterrows():
distance = geodesic((
ediya['lat'],
ediya['lng']),
(starbucks['lat'], starbucks['lng'])).meters
if distance <= 200:
count += 1
break
data.append(bool(count))
ediya_df['근처 지점 존재 유무'] = data
ediya_df.head()
구별 이디야 매장 개수와 스타벅스 매장 개수 정리
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
rc('font', family='Arial Unicode MS')
get_ipython().run_line_magic('matplotlib', 'inline')# 구별 이디야 매장 개수와 스타벅스 매장 개수
rank_gu = ediya_df['구'].value_counts().reset_index()
rank_gu.columns = ['구', '이디야 지점 개수']
rank_gu_starbucks = starbucks_df['구'].value_counts().reset_index()
rank_gu['스타벅스 지점 개수'] = rank_gu_starbucks['count']
rank_gu.head()
구별 이디야 매장 근처 스타벅스 매장 존재 유무 개수 정리
# 구별 매장 존재 유무 개수 정리
grouped_df = ediya_df.groupby(['구', '근처 지점 존재 유무']).size().reset_index(name='총 데이터 개수')
grouped_df.head()
plt.figure(figsize=(12, 8))
fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True)
fig.subplots_adjust(hspace = 0.05)
sns.barplot(x='구', y='이디야 지점 개수', data=rank_gu, color='blue', ax=ax1, alpha=0.5, zorder=1)
sns.barplot(x='구', y='스타벅스 지점 개수', data=rank_gu, color='green', ax=ax1, alpha=0.5, zorder=1)
sns.barplot(x='구', y='총 데이터 개수', hue='근처 지점 존재 유무', data=grouped_df, ax=ax2, palette='Set1')
ax1.set_ylim(10, 100)
ax2.set_ylim(0, 30)
ax1.set_ylabel('지점의 수')
ax2.set_ylabel('근처 200m내 스타벅스 지점 존재 여부')
plt.setp(ax2.get_xticklabels(), rotation=45, ha='right', fontsize=8)
plt.show()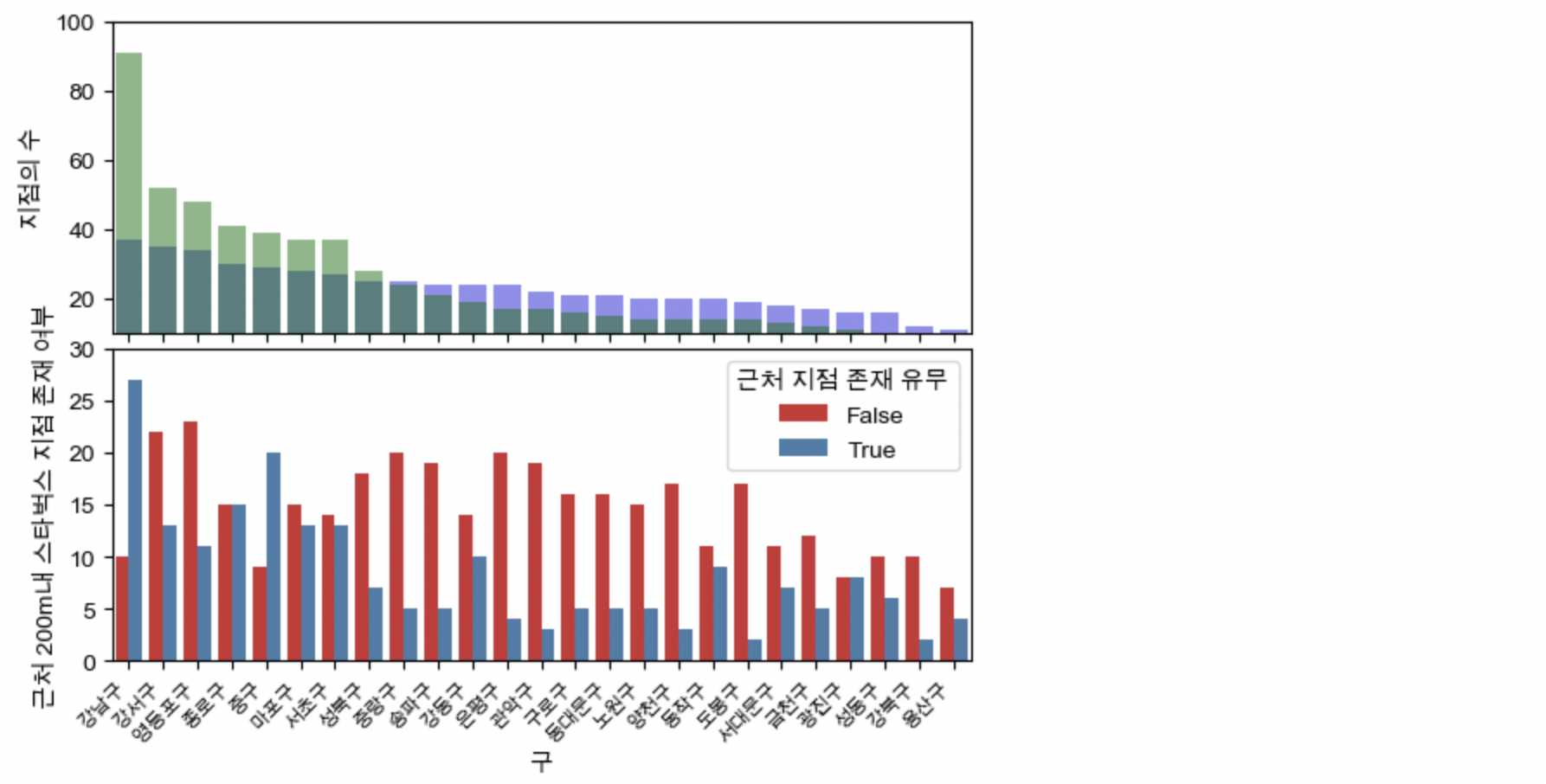
결론
이디야 매장의 위치는 스타벅스 매장의 위치와 연관성이 없다.
이디야 매장이 스타벅스 매장의 위치와 연관성이 있다고 판단하기 위해서는 서로 인접한 매장의 수가 많아야 한다.
하지만 인접한 매장의 수가 많은 강남구와 중구는 스타벅스와 이디야 매장의 수가 많은 1위, 3위 지역이며
그 외 지역에서는 전체 매장의 수에 비해 상호 근처에 존재하는 매장의 개수가 유의미하다고 보여지지 않는다.
내일의 학습목표
EDA 시계열분석 1 - 2



